
17 Abr Análisis de datos y confirmación de hipótesis de estacionalidad en productos de Farmacia
Introducción al estudio
Después de varios años inmerso en el ámbito como consultor de negocio para la industria farmacéutica, he podido observar cómo las distintas farmacias sostienen la existencia de productos estacionales, contrastando con aquellos que mantienen una demanda constante a lo largo del año.
Evidentemente, verificar esta afirmación es tan sencillo como analizar la fluctuación de los niveles de stock en sus sistemas de gestión durante determinadas temporadas. Además, es comúnmente aceptado que las ventas de productos como los protectores solares se incrementan significativamente antes y durante el verano, mientras que aquellos dirigidos a la prevención de resfriados experimentan un aumento durante los meses más fríos del año.
El presente estudio se centra en confirmar dicha hipótesis, basándose en el análisis del histórico de ventas de un número «n» de farmacias.
Con este propósito, se ha formulado una hipótesis que denominaremos «Hipótesis sobre la Estacionalidad».
Autor: Miguel Ángel García
Consultor de Negocio y CEO eXtremaNET
magarcia@extremanet.com
Objetivos
El objetivo principal es confirmar la hipótesis sobre la estacionalidad en productos farmacéuticos, específicamente aquellos destinados al tratamiento de gripes y resfriados. Este análisis podría proporcionar valiosa información para la gestión de inventarios y permitir la identificación de patrones estacionales en otras categorías de productos, enriqueciendo así las estrategias comerciales y mejorando la atención al cliente.
Información sobre el Dataset
Resumen
- Nombre del Dataset: ventas.csv (datos propios )
- Contenido: Histórico de Tickets de Venta de 2 farmacias.
- Filas: +1 millón de filas
Descripción del contexto
Este conjunto de datos recoge registros históricos de ventas de dos farmacias a lo largo de varios años, obtenidos mediante consultas SQL realizadas manualmente a la base de datos.
Los datos abarcan detalles como fechas y horas de las ventas, información sobre los productos, sus respectivas familias, referencias, identificadores de clientes e iniciales, códigos postales de los clientes, unidades vendidas y precios de venta al público (PVP).
Es importante destacar que los tickets pueden contener múltiples líneas, lo que implica que un pedido puede comprender varios productos diferentes. Por lo tanto, es común que el código de pedido se repita en varias líneas de la base de datos.
Metadatos
| CAMPO | COMENTARIOS | TIPO |
| FARMACIA | String valores posibles | DISCRETA/CATEGORICA |
| PEDIDO | String | DISCRETA/CATEGORICA |
| FECHA | Formato dd/MM/yyyy | VARIABLE CONTINUA |
| HORA | Formato HH:mm | DISCRETA/CATEGORICA |
| IDCLIENTE | String, puede contener nulos o blancos | DISCRETA/CATEGORICA |
| CLIENTE | String, puede contener nulos o blancos | DISCRETA/CATEGORICA |
| CODPOSTAL | String, puede contener nulos o blancos | DISCRETA/CATEGORICA |
| REF | String 6 caracteres . Referencia producto | DISCRETA/CATEGORICA |
| FAMILIA | String, puede contener nulos o blancos | DISCRETA/CATEGORICA |
| PRODUCTO | String con el nombre del producto | DISCRETA/CATEGORICA |
| UDS | Int, puede tener negativos y positivos. | VARIABLE CONTINUA |
| PVP | Decimal. Precio del producto | VARIABLE CONTINUA |
Muestra de los datos
El fichero trae metadatos y los valores de las filas vienen separados por punto y coma ; y los campos con String no vienen entre comillas dobles. Los valores decimales vienen con punto en la separación decimal

Formulación de hipótesis a demostrar
Una hipótesis que podríamos plantear basada en este conjunto de datos es la siguiente:
«La demanda de productos farmacéuticos varía según la temporada del año, con un aumento significativo durante la temporada de gripes y resfriados»
Justificación de la relevancia
Este conjunto de datos se revela como crucial para respaldar nuestra hipótesis, dado que proporciona una visión detallada de las ventas de medicamentos en el sector farmacéutico a lo largo del tiempo. Demostrar una relación significativa entre las ventas de medicamentos para resfriados y gripe y la época del año podría acarrear beneficios tanto para las farmacias como para los consumidores.
Las farmacias, al tener acceso a estos datos, podrían ajustar sus inventarios y estrategias de marketing según los hallazgos obtenidos. De esta manera, podrían anticipar y satisfacer la demanda de los consumidores, ofreciendo una mayor disponibilidad de productos durante las temporadas de enfermedades.
Por su parte, los consumidores se beneficiarían al tener a su disposición una amplia gama de medicamentos necesarios durante períodos específicos del año, lo que contribuiría a una mejor atención de su salud.
Beneficios y relación con los ODS de la Agenda 2030:
Este análisis podría beneficiar a la sociedad de varias maneras:
- ODS 3: “Salud y Bienestar”: Los productos farmacéuticos están directamente relacionados con la salud de las personas. Al ayudar a garantizar un suministro adecuado de estos productos, se contribuye al ODS número 3.
- ODS 12: “Producción y Consumo Responsables”: Al reducir el desperdicio de productos farmacéuticos se promueven prácticas sostenibles y evita el derroche de recursos.
Resultados previstos
El objetivo primordial es identificar una relación significativa entre las ventas de productos destinados al tratamiento de gripes y resfriados y las estaciones del año. Este descubrimiento, de ser confirmado, fortalecería nuestra hipótesis y nos proporcionaría información invaluable para la gestión efectiva de inventarios.
Además, este análisis nos permitiría potencialmente identificar patrones estacionales en otras categorías de productos farmacéuticos, ampliando así nuestro entendimiento sobre el comportamiento del mercado en diferentes épocas del año. Estas perspectivas enriquecerían nuestras estrategias comerciales y nos capacitarían para anticipar y responder de manera más eficiente a las necesidades de los consumidores en distintos momentos del ciclo anual
Análisis de Sesgos
- Sesgo de estacionalidad: Se deben considerar datos de diferentes períodos del año, si no es así, podría haber un sesgo en la identificación de patrones estacionales.
- Sesgo geográfico: Si no se tienen datos de muchas Farmacias localizadas en diferentes puntos geográficos, los datos tan solo representan a una zona y no son generalizables. (No es lo mismo vivir en Tenerife que en A Coruña)
Tecnología e Itinerarios propuestos
Se ha realizado en Python sobre Visual Studio Code y está esquematizado para mejor su compresión
Para este estudio se ha organizado en 3 itinerarios
Itinerario A: Modelado Descriptivo
Hacemos procedimientos para la exploración del dataset con numerosos gráficos e informes que ayudan a entender en funcionamiento de las ventas de una farmacia y el comportamiento de los inventarios. Casi 20 informes y gráficas que aportan mucho valor como función divulgativa y permitiría presentar datos de interés a stakeholders. Se usan se añade técnicas de clustering con K-Mean que incluye el cálculo de coeficiente con Silhoutte para la clasificación precio los productos en 5 grupos conocidos.
Itinerarios B y C : Modelado Predictivo
Posteriormente gracias al el análisis de patrones frecuentes, que tiene como objetivo conseguir un “recomendador” gracias al algoritmo a priori, nos permite obtener como resultado reglas de asociación de productos.
Por otro lado, se desarrollan otros apartados relacionados con Clasificación y la Regresión.
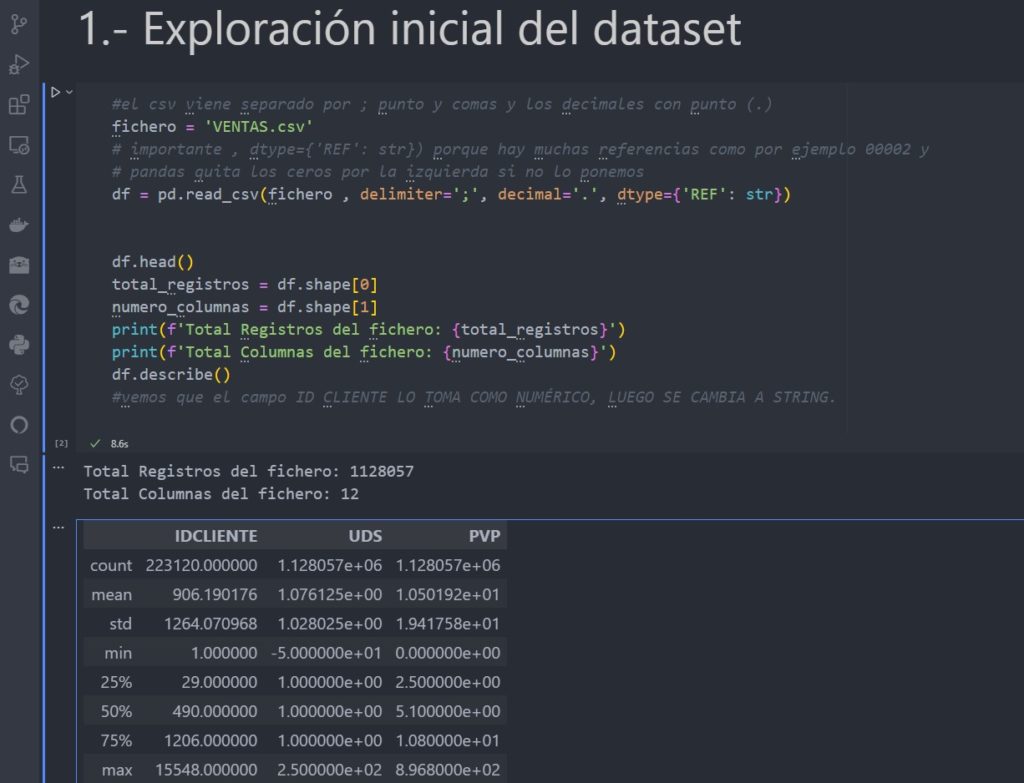
Exploración inicial de datos
Contamos para este ejemplo con un fichero reducido de más de 1 millón del íneas
Preprocesamiento de datos
Se muestra a continuación como se ha hecho el procesamiento de datos :
- Preprocesamiento
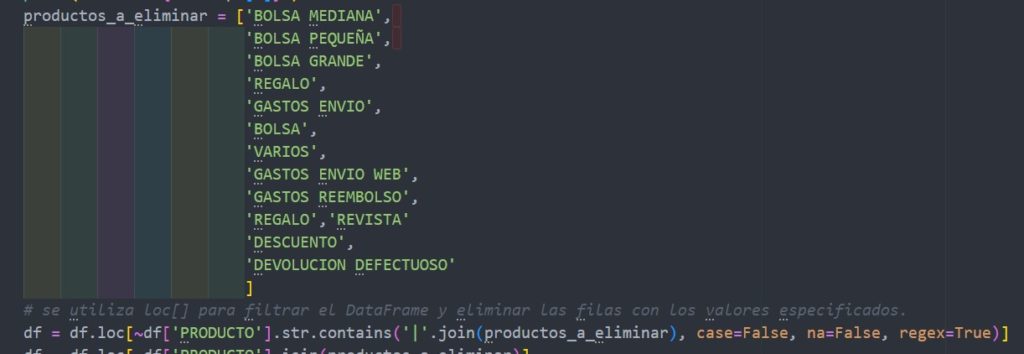
- Mapeo y eliminación inicial de datos no deseados
Gracias al conocimiento de dominio, podemos eliminar registros no necesarios sin importancia.
Transformación
Agregamos el campo ‘Tipo Producto’ al DF principal
Los productos de Parafarmacia suelen ser aquellos cuya REF está por debajo del codigo 600.000 y los Medicamentos tienen referencias mayor del 600000 ( normalmente )
-
- Agregamos campo tipo producto
- Convertir datos a String
- Formato de fechas y campo mes
- Split entre Medicamentos y Parafarmacia



Discretización
Obtención de columnas numéricas y categóricas

Matriz de correlación
Creamos una matriz de correlación que servirá para ver visualmente valores atípicos en las variables y poder tratar outliers mejor
Observando que la relación entre las variables numéricas no tienen mucha relación ya que «hablan» sobre precio y stock lo cual no tiene mucha relación entre si

Tratamiento de Outliers
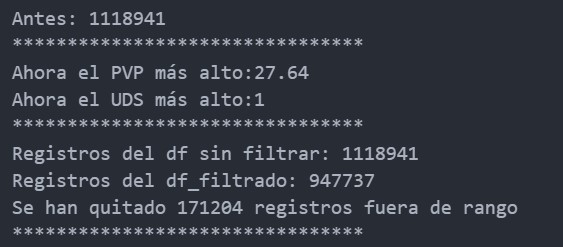
A continuación se ejecutan procedimiento para el tratamiento de outliers como quitar datos faltantes, eliminar registros fuera de rango, registro PVP máximo, registro UDS máximo
Tratamiento estadístico de Outliers
Adicionalmente se realizan ajustes al dataset de entrada para limitar los registros teniendo en cuenta técnica de eliminación de outliers como el uso de cuartiles estableciendo límite de UDS límite de PVP y obteniendo nuevos valores máximos
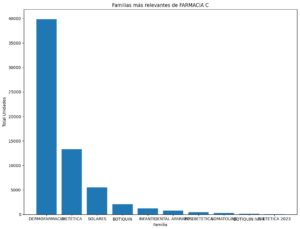
Exploración de Datos (INTINERARIO A)
En este punto del estudio se hacen más de 20 gráficas e informes que muestran datos como tickets medio, pedidos por farmacia, por categoria, por meses, las familias más relevantes, mapa de calor, medias, registros anuales y muchos otros.
Se extraen conclusiones importantes acerca de la venta de productos.



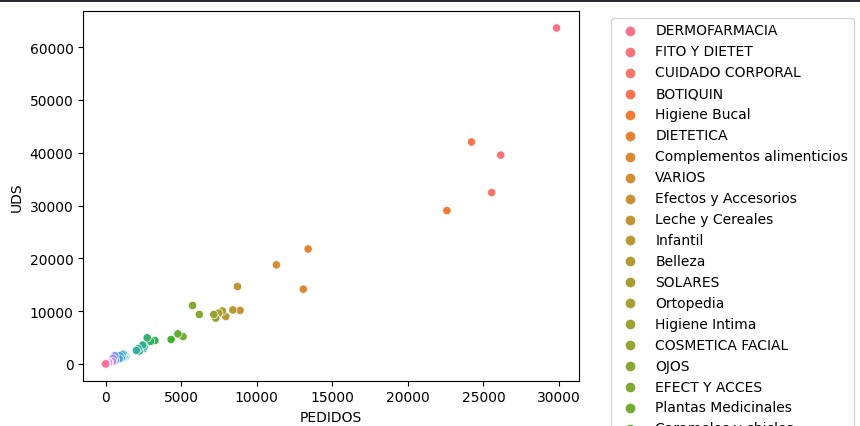
Agrupamiento
El estudio incluye numerosos informes sobre agrupamiento como este en donde se ve claramente el grupo de productos más vendido.

y si nos detenemos solamente en Parafarmacia
Técnicas de modelado escogidas
Aunque no está incluido en este estudio, se ha elegido el modelado predictivo para este proyecto, tanto para la clasificación como la regresión. Inicialmente, dentro de este contexto primero se usa el algoritmo apriori para intentar extraer reglas de asociación y luego se entrenan los modelos necesarios la clasificación y la regresión. Además como practica adicional ,se incluye KMeans
Modelado descriptivo usando K-Means
 K-Means es un algoritmo no supervisado de Clustering que se utiliza cuando se tienen muchos datos sin etiquetar. Aunque no es el caso de mi CSV, me ha parecido interesante para observar su compartimiento. El objetivo K-Means es asignar cada fila un grupo K basado en sus características que se agrupan en base a la similitud de las columnas.
K-Means es un algoritmo no supervisado de Clustering que se utiliza cuando se tienen muchos datos sin etiquetar. Aunque no es el caso de mi CSV, me ha parecido interesante para observar su compartimiento. El objetivo K-Means es asignar cada fila un grupo K basado en sus características que se agrupan en base a la similitud de las columnas.
Para este caso agruparemos los productos por su media de precio en 5 grupos. También se incluye el cálculo de coeficiente con Silhoutte cuyo resultado es 2.
Mediante K-Means se verán agrupaciones en clúster diferentes productos con diferentes precios y ejecutaremos un ejemplo de en qué grupo estará un producto según un precio.
Algoritmo a priori
El algoritmo apriori se ha utilizado para encontrar reglas de asociación entre elementos en transacciones de venta. Es decir, lo que se intenta es descubrir patrones de compra en una farmacia.
La idea es primero limpiar y formatear los datos, lo cual se hace en la primera parte del código, posteriormente se agrupan los registros para que sean únicos, luego se usa codificación onehote para convertir los datos en una matriz binaria, (matriz invertida) en donde básicamente cada celda contiene un 1 si el producto está en la transacción y 0 si no está.
Por último, se ejecuta el algoritmo que permitirá descubrir qué productos tienden a comprarse juntos.
Una vez se ejecutó el algoritmo e identificados los patrones dichos patrones se guardan en un fichero CSV para facilitar su compresión posteriormente.
Clasificación y Regresión
En este proyecto se exploran distintos algoritmos de clasificación y regresión
Uso y objetivos:
- 1º Clasificación: predecir PRODUCTO (variable categórica)
- 2º Regresión: predecir UDS (variable continua)
Clasificación
Primero creamos un dataframe solo con las ventas agrupadas por PRODUCTO y al igual que antes, primero se limpia, formatea y se preparan los datos para la clasificación, en segundo lugar, se identifican las variables dependientes e independientes. Se usa la convención de llamar `X` al dataframe con las variables predictoras e `y` a la variable a predecir.
Luego entrenamos los modelos:
- Naive Bayes
- Support Vector Machines
- Decision Tree
- Random Forest
- Redes Neuronales (Multi-layer Perceptron)
Regresión Lineal
Primeros preparamos los datos agrupando de los datos por referencia y fecha, consiguiendo sumas totales de pvp y unidades por fecha y referencia.
En segundo lugar, dividimos el conjunto de datos con características (X) y UDS en (Y) que es la variable objetivo.
Luego para que no tarde demasiado, nos quedamos con los 25 productos más vendidos para hacer las predicciones.
Entrenamos los modelos:
- Regresión Lineal
- Regresión Polinómica
- Regresión Ridge
- Regresión Lasso
- Árboles de Regresión
- Random Forests (con árboles de regresión)
- Redes Neuronales (Multi-layer Perception)
Usamos Random Forest y mostramos las predicciones de las unidades para los productos más vendidos.
Por último, Además hacemos usamos Regresión Lineal para intentar predecir las unidades necesarias para los próximos 5 días.
(*) Los resultados de este análisis son confidenciales y no pueden mostrarse
Resultados obtenidos sobre hipótesis de “Estacionalidad”
«La demanda de productos farmacéuticos varía según la temporada del año, con un aumento significativo durante la temporada de gripes y resfriados»
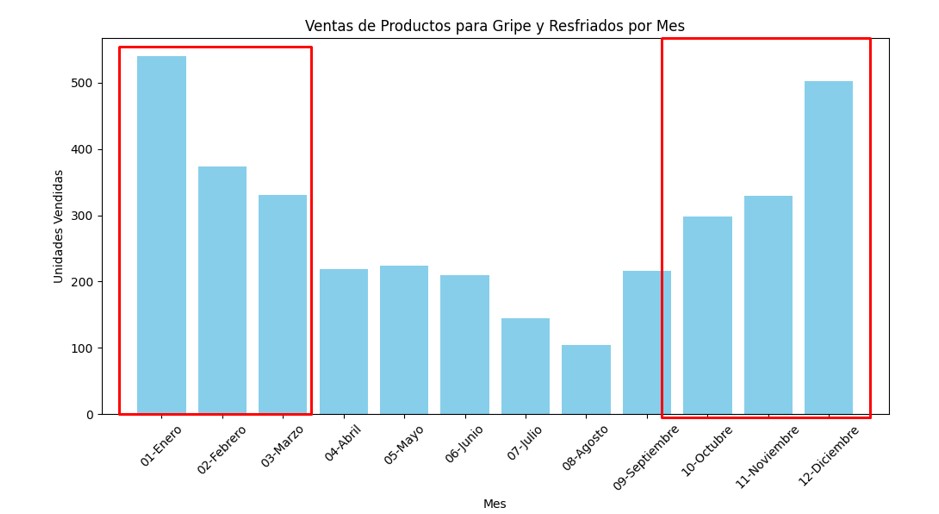
Para determinar si los productos relacionados con la gripe y los resfriados son más vendidos en los meses más fríos tenemos en cuenta que en España la temporada de gripe se cuenta habitualmente desde la semana 40 a la 20 Ver fuente
Pasos seguidos para demostrar la hipótesis y conclusiones
- Primero hemos definido cuál o cuáles son los productos más comunes relacionados con el resfriado y la gripe creando un array con ellos.
- Después, hemos filtrado las ventas de estos productos y las hemos agrupado por meses.
- Por último, visualmente, se aprecia que los productos relacionados con la gripe y los resfriados se venden más en la temporada de los meses entre octubre y mayo
 Por otro lado:
Por otro lado:
- Hemos creado un array con los meses de Gripe y Resfriado
- Hemos creado un array con el resto de los meses
- Hemos agrupado y filtrado los datos para comparar las ventas de los productos entre los diferentes meses de año.
Demostración
Gracias a las agrupaciones y el filtrado de productos, visualmente, se aprecia que los productos relacionados con la gripe y los resfriados se venden más en la temporada de los meses entre octubre y mayo. Podríamos afirmar que se demuestra que :
“la venta de productos relacionados con la Gripe y Resfriados se dispara en los meses fríos.”
Bibliografía consultada
- “Python para análisis de datos” de ANAYA del autor Wes McKinney
- Página web: https://docs.python.org/es/3/
- “Aprende Machine Learning” del autor Juan Ignacio Bagnato
No ha comentarios en este momento